Original article published on Substack on April 7m 2026.
For years, data security accepted inaccuracy as a given. AI didn’t create that problem. It just removed the ability to ignore it.
For a long time, there has been an unspoken assumption in enterprise data security: accuracy is limited, and that is simply the way it is.
Everyone knows it, even if few say it out loud. Detection systems generate noise, policies are imprecise, and context is often missing. Yet the industry has learned to operate within those constraints, treating them less as a flaw and more as a reality of the domain. Like a chronic condition you manage rather than cure.
Over time, this shaped how data security programs were actually used. The goal was no longer precise control, but partial visibility, best-effort detection, and selective enforcement where the risk of being wrong was low enough. And in many organizations, even that proved too ambitious.
Technologies were deployed but never fully turned on. Policies were configured but heavily narrowed. Entire categories of controls, especially those that could interfere with business workflows, were avoided. It is not uncommon to see large enterprises with powerful platforms already in place, but used mainly for reporting or limited edge cases. Tools like Microsoft Purview often fall into this category, not because they lack capability, but because enforcement based on them is perceived as too risky, not from a security standpoint, but from a business disruption standpoint.

Inaccuracy was tolerated because enforcement was optional
In a pre-AI world, this compromise was workable. Humans were still in the loop, and workflows had natural checkpoints. Decisions could be reviewed or corrected after the fact. If a system generated too many false positives, it created friction, but rarely broke the business.
So organizations adapted. Detection became the primary objective, enforcement was limited to narrow, high-confidence scenarios, and manual review filled the gaps. Over time, data security shifted from controlling risk to observing it. Because everyone operated under the same constraints, the lack of accuracy stopped being treated as solvable. It became part of the landscape.
AI did not create the problem. It exposed it.
AI, copilots, and agent-driven workflows did not introduce inaccuracy into data security. That problem was already there. What AI changed is the tolerance for it.
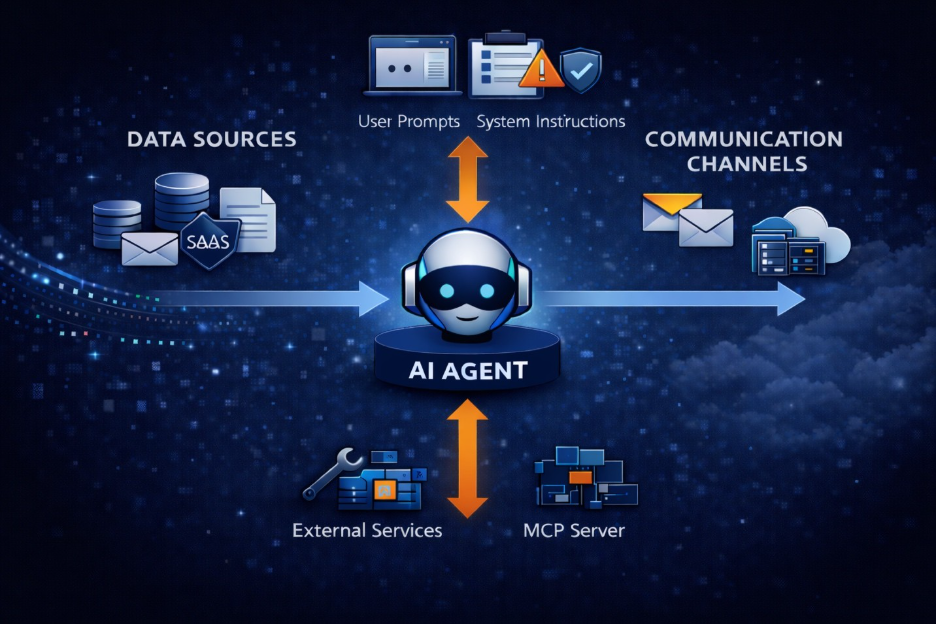
In AI-driven environments, content is continuously generated, transformed, and acted upon. Decisions happen inside workflows rather than after them, often by non-human actors at scale. There is no natural pause for manual review, and no clear boundary where inspection can be deferred. If a control is not applied in-line, it is effectively not applied at all.
That makes enforcement no longer optional, and enforcement requires accuracy.
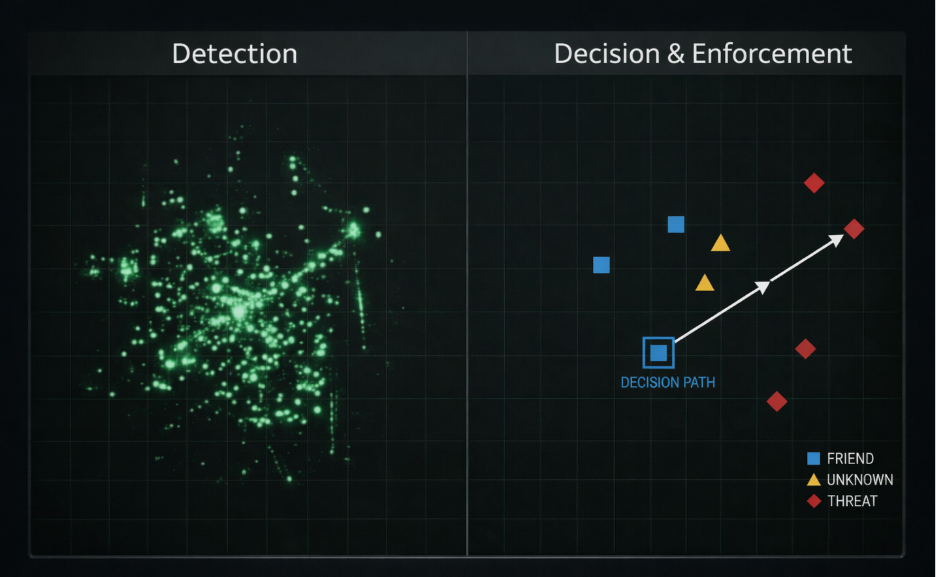
Detection is easy. Enforcement is hard.
Detection answers a relatively simple question: what might this be? Enforcement requires answering a harder one: what is this, in this specific context, and what should happen?
Traditional approaches were never designed for that second question. Patterns, keywords, and shallow classification can identify signals, but they struggle to determine whether something is actually sensitive in a given situation, whether the recipient is appropriate, or whether the action should be allowed, blocked, or modified. Without those answers, enforcement becomes guesswork, and guesswork does not scale.
Why “good enough” is not good enough
There is a common belief that incremental improvements in accuracy will make enforcement viable. In practice, that rarely holds. Enforcement is highly sensitive to error.
A false positive interrupts real work, frustrates users, and leads to exceptions and workarounds, eventually eroding trust. A false negative results in actual exposure.
Faced with this trade-off, organizations respond predictably. They reduce enforcement scope, introduce manual approval steps, or fall back to monitoring. Gradually, enforcement fades out, not because it is not needed, but because it is not reliable enough.
The real problem is lack of context
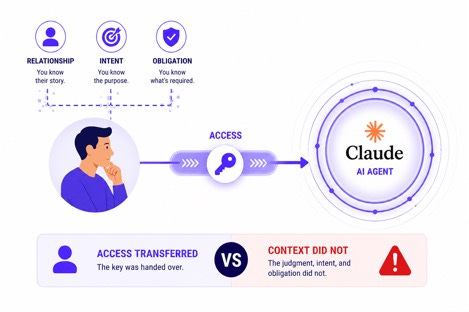
At the core of this challenge is not just model accuracy. It is contextual understanding.
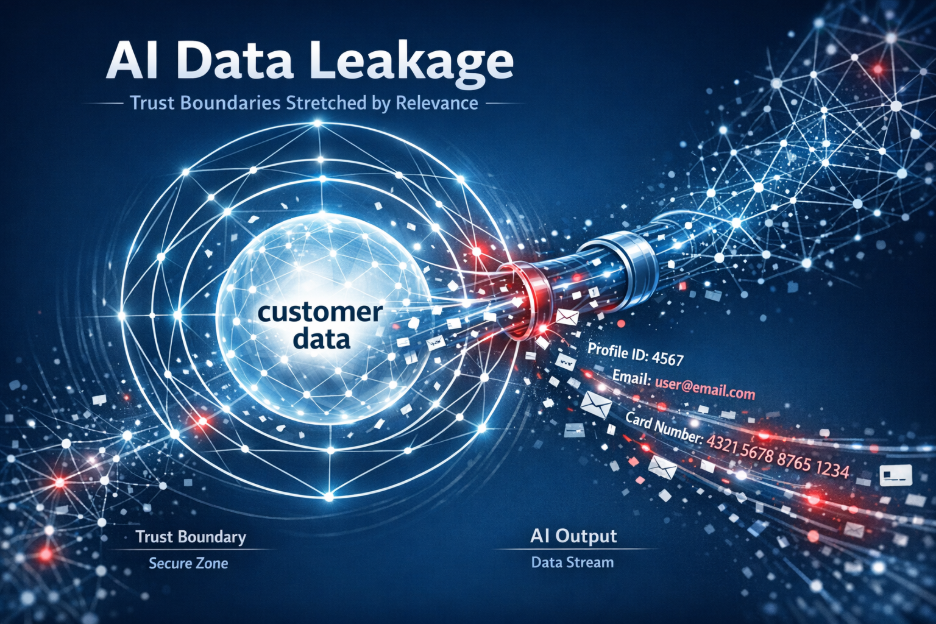
Most systems evaluate content in isolation. They identify patterns, classify documents, or detect entities. But real decisions depend on relationships and intent. The same piece of data can be acceptable in one workflow and a violation in another.
Sending customer information to the customer may be expected. Sending that same information to a third party may be a breach. Without understanding who the data is about, who is involved, and what the business context is, the system cannot make the correct decision. And without correct decisions, enforcement cannot be trusted.
From chronic limitation to solvable problem
For years, this lack of accuracy was treated as an inherent limitation, something to manage rather than solve. AI changes that assumption in two ways.
First, it raises the stakes. In AI-driven workflows, there is no effective control without accurate, in-line decisions.
Second, it changes what is technically possible. Advances in content understanding, entity awareness, and contextual analysis make it increasingly feasible to approach this differently. What was once seen as an incurable condition begins to look like an engineering problem.
From detection systems to control systems
Data security is shifting from systems designed to detect and report, to systems expected to decide and enforce. Detection systems can tolerate ambiguity. Control systems cannot.
To function as a control layer, a system must be accurate enough to take action consistently across workflows, without constant human intervention. That is a higher bar, but it is also the only one that matters if the goal is real risk reduction.
No accuracy, no enforcement. No enforcement, no control.
The industry is now at an inflection point. The longstanding acceptance of inaccuracy is no longer compatible with how data is used in modern environments. AI did not introduce that tension, but it made it impossible to ignore.
The relevant question is no longer how much you can detect, but what you can enforce reliably, at scale, without breaking the business. Because ultimately, only one thing reduces risk.
Control.
And control is only possible when accuracy is high enough to support it.
Accuracy is not a feature. It is the foundation that turns data security from observation into control.


%20(3).png?width=200&height=200&name=Bonfy-YB-Icon%20(200%20x%20200%20px)%20(3).png)