Original article published on Substack on March 31, 2026.
Why metadata context is no longer enough
Data security has spent years getting better at context.
Most modern systems can tell you who accessed data, where it lives, what system it came from, and under what permissions it was used. Identity, ownership, location, device posture, application context. These signals have become the foundation of how we control data.
They are useful. They explain the environment around data.
But they miss something fundamental.
They do not explain the meaning of the information itself.
That gap is becoming critical.
As AI systems increasingly retrieve, assemble, and generate information across enterprise workflows, security decisions can no longer rely only on metadata about stored objects. They must rely on understanding the semantics of the information being created and shared.
In that environment, AI data security is becoming a context engineering problem.

The Model We Built Around Files
Traditional data security was designed around a simple assumption. Enterprise data exists primarily as stored objects.
Documents, files, and structured records live in repositories. Security systems attach metadata to those objects and use it to control access and movement.
This model works well in that world.
A file has an owner, a location, and permissions.
But metadata describes the environment around data, not the information itself.
A document can be owned by the right user, stored in the right place, and accessed with valid permissions. From a metadata perspective, everything looks correct.
Yet the content may reference the wrong customer, combine information from multiple accounts, or include details belonging to another entity.
In those cases, the risk is not about access control. It is about the relationships embedded in the information.
AI Breaks the File-Centric Assumption
AI systems operate differently.
Information is no longer just retrieved or moved. It is assembled.
Prompts, chat interactions, retrieved fragments, and generated responses often exist only briefly. In many cases, the information being evaluated never existed as a single stored document.
An AI assistant may retrieve fragments from internal documents, combine them with a user prompt, incorporate data from SaaS systems, and generate a response that is then shared.
The resulting information may contain relationships that were never explicitly stored anywhere.
This breaks a core assumption of traditional context.
File-level metadata captures only a small part of what matters, because the most important information may never exist as a file.
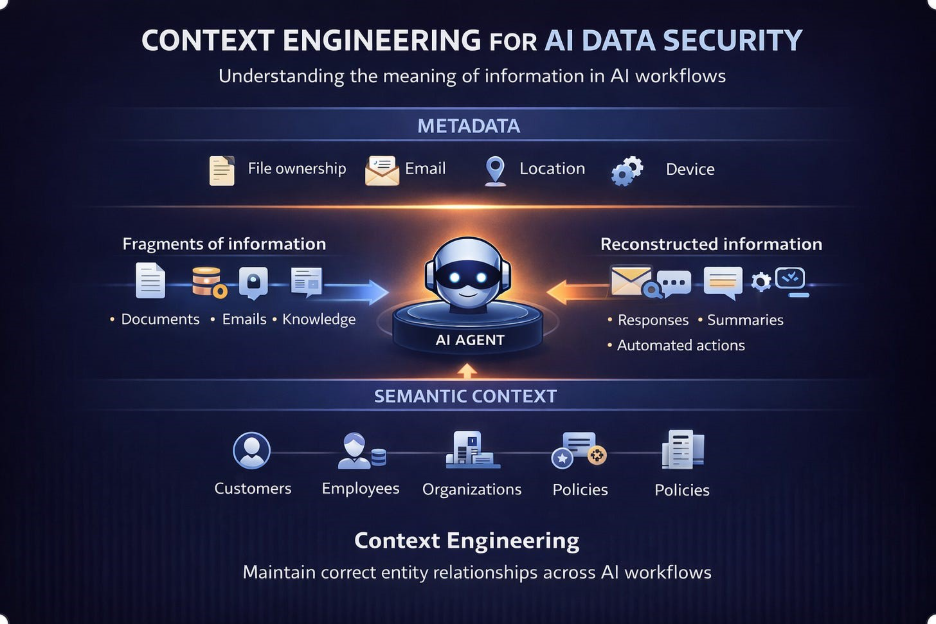
Context Is About Meaning
To govern these environments, security systems must understand semantic context.
Context is not just who accessed a file or where it came from. It is the meaning carried by the content and the relationships it expresses.
A useful way to think about this is the “who” dimension of data security. Not just what the data is, but which people, customers, or business entities it refers to.
This entity dimension anchors context.
When systems understand which entities appear within information, they can reason about whether an action makes sense.
The same information may be appropriate in one interaction and a serious issue in another. The difference comes down to the entities involved.
AI Introduces a New Failure Mode
AI does not just make this harder. It introduces a new type of risk.
A single interaction may involve retrieving fragments from several sources, combining them with user input, generating new output, and sharing it across channels.
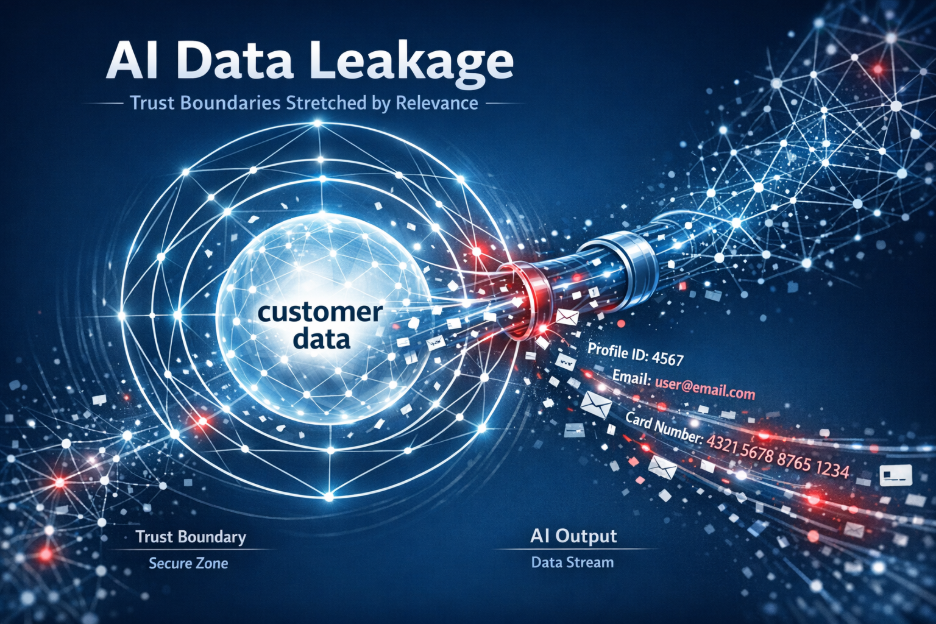
The result is derived information.
Without understanding the entity relationships in that output, security systems may detect sensitive data while missing the key question. Whether the information refers to the correct entities in the correct context.
This creates a new failure mode.
A generated response may reference the wrong customer, combine insights from multiple accounts, or expose internal knowledge that should never appear together.
From a metadata perspective, everything may look normal. From a contextual perspective, the outcome may be completely wrong.
Why Entity Context Changes Policy
This is not just a modeling issue. It directly affects how policies work.
Consider a customer-facing workflow. A support agent retrieves policy details for the customer they are assisting. That is legitimate.
If the same information appears in another customer interaction, it becomes a problem immediately.
Without entity context, both scenarios look identical.
Entity awareness allows organizations to express policies that reflect real business relationships. Which employees can access which customer data, under what circumstances, and for which interactions.
It also improves precision. Policies can focus on real risk scenarios instead of broad pattern matching, reducing noise and friction.
Most importantly, it protects customer trust.
Organizations do not lose trust because they mishandled a pattern. They lose trust because information about one customer appears in the context of another.
From Detection to Context Engineering
In the AI world, “context engineering” refers to structuring information so systems understand what matters for a task.
Data security is entering a similar phase.
To govern AI-driven workflows, organizations must construct and maintain context that reflects real-world relationships between users, customers, accounts, and business entities.
This goes beyond attaching metadata to stored files.
Security systems must identify entities within content, preserve those relationships as information moves through workflows, and ensure that generated outputs maintain the correct context.
The problem is no longer just detecting sensitive data.
It is maintaining the semantic integrity of information as it is retrieved, assembled, and generated.
The Scale Problem
This challenge becomes harder at scale.
Large organizations operate across millions of entities and multiple systems. AI agents and copilots interact with these systems continuously, retrieving information, assembling context, and generating outputs.
Each interaction may involve multiple entities. The user initiating the task, the recipient, and the customers or accounts referenced within the content.
Maintaining correct context across these interactions requires systems that can reason about entity relationships at enterprise communication speed.
Without that capability, organizations may detect sensitive data exists while still missing whether the context is correct.
Looking Ahead
For years, data security has largely been treated as a classification problem.
Those capabilities still matter.
But as AI systems increasingly assemble and generate information, they are no longer sufficient.
Metadata describes the environment around data.
Context explains the meaning of the information.
As AI becomes embedded in everyday workflows, the ability to engineer and preserve that meaning will become essential.
AI data security is no longer only about identifying what data is sensitive.
It is about understanding what the information means, which entities it refers to, and whether that context remains correct as information is reconstructed across workflows.
In that sense, AI data security is becoming a context engineering problem at scale.


%20(3).png?width=200&height=200&name=Bonfy-YB-Icon%20(200%20x%20200%20px)%20(3).png)