Article originally posted on Substack on April 29, 2026.
Why AI-mediated access is challenging long-held control assumptions
Enterprise discussions about AI security often focus on model risks: prompt leakage, misuse, hallucination, or governance controls around the AI application itself.
Important as these concerns are, they can obscure a deeper shift emerging with connected AI systems such as Claude Enterprise.
The larger issue may not be the model.
It may be the architecture.

The Execution Point Moved
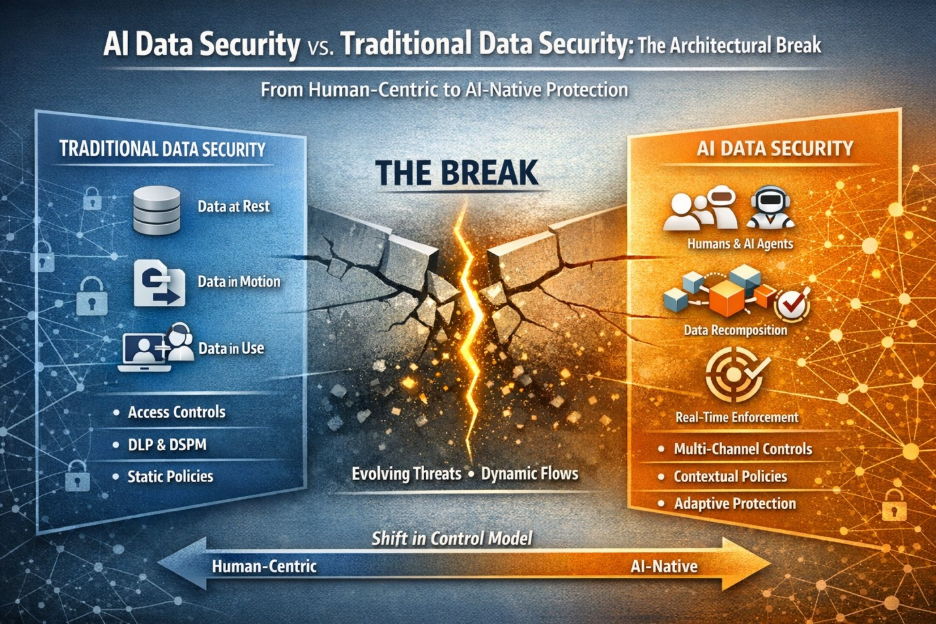
For years, enterprise data security has been organized around control points tied to where users work and where data moves: endpoints, browsers, networks, SaaS applications, and repositories. Classification, DLP, access controls, and CASB evolved around that operating model. While imperfect, these controls were broadly aligned with where meaningful data activity occurred.
Connected AI begins to pressure test those assumptions.
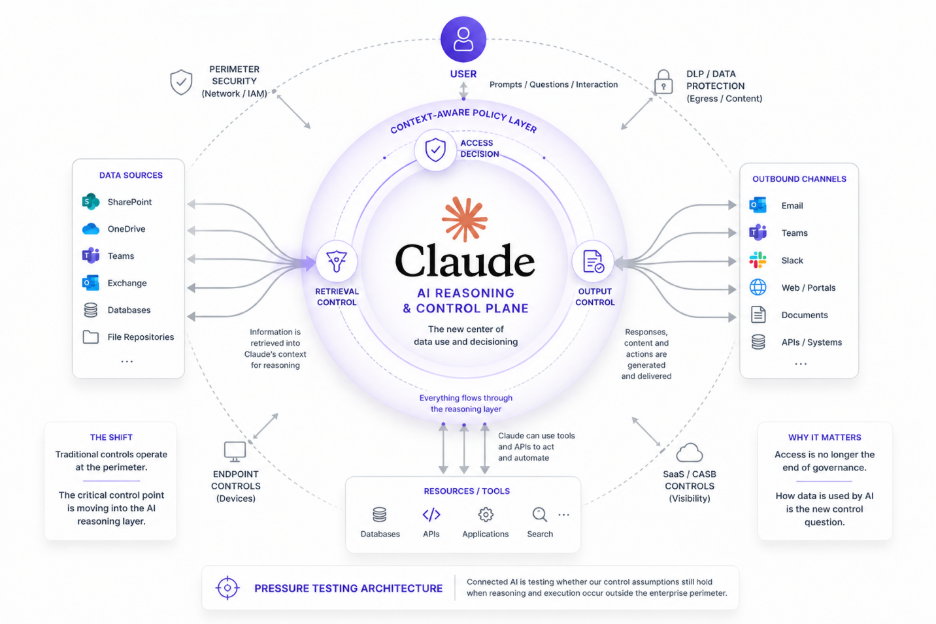
When Claude is connected to systems such as Microsoft 365, a user interaction can trigger far more than retrieval. Information may be pulled from repositories, assembled into transient working context, reasoned over inside Claude’s execution environment, saved in shared memory and synthesized into generated output before the user sees a response.
This is not simply another application workflow.
It reflects a shift in where meaningful data use may occur.
The enterprise may still own the data, but increasingly does not fully own the execution path through which that data is used.
That is part of the architectural break.
And it is as much technical as conceptual.
Many existing controls remain valuable, but they were largely designed for environments in which the relevant handling of sensitive data occurred within enterprise-controlled or enterprise-observable boundaries. Connected AI complicates that model by moving portions of retrieval, reasoning, and synthesis into external execution planes where traditional controls may see only partial signals.
The significance is not that controls have suddenly failed.
It is that they are being tested against assumptions they were not designed to carry.
That pressure test is revealing something important.
Permissions Are Not the Whole Policy
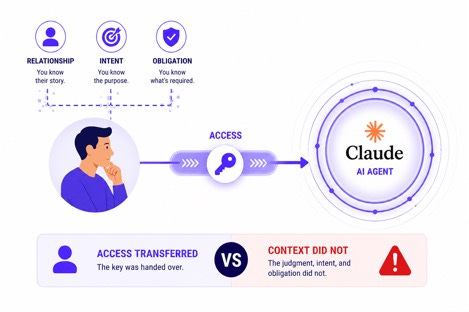
Historically, much of data security centered on whether a user should be allowed to access information.
Connected AI introduces a different question:
Should an AI system be allowed to use that information in a particular context?
The distinction is subtle, but consequential.
A permission model may determine that a user can access a customer document.
It does not necessarily determine whether an AI system should retrieve that document into a reasoning workflow, combine it with other information, and use it in generated output.
Access and policy begin to diverge.
Or more precisely, access increasingly becomes a policy problem.
That shift matters because it suggests the critical control decision may be moving closer to the moment data is selected for AI use, rather than residing solely in traditional repository permissions or downstream detection controls.
This is also where connected AI is reshaping the familiar west-east problem of data access itself, not merely adding a separate north-south control-plane problem on top of it.
Retrieval is no longer just access.
It may be the start of reasoning.
And that changes what governance may need to consider.
What Claude Is Pressure Testing
Seen this way, connected AI is not simply adding another risk surface.
It is pressure testing whether existing control architectures are positioned at the right place in the workflow.
That is a much deeper question.
And it extends well beyond Claude.
The same pattern is beginning to emerge across ChatGPT Enterprise, Copilot Studio, and broader agentic systems.
Claude simply makes the shift easier to observe.
It exposes that protecting where data resides and where it moves, while still necessary, may no longer be sufficient to govern how information is used inside AI-mediated workflows.
That does not completely invalidate existing architecture.
But it may point to the beginnings of a new layer.
One concerned not only with protecting data, but with governing how AI systems are allowed to use it.
Why That’s a Good Thing
Pressure tests expose weaknesses, but they also reveal where architecture must evolve.
Connected AI may be doing precisely that for data security.
It is surfacing questions that were always latent, but easier to ignore when applications, execution, and enforcement largely occupied the same place.
Where should policy be enforced when access, reasoning, and generation increasingly occur across an execution surface the enterprise does not fully own?
That may prove to be one of the defining data security questions of the AI era.
And that is why this pressure test is a good thing.
It is not merely exposing stress in existing controls.
It is clarifying where the next layer of architecture may need to emerge.


%20(3).png?width=200&height=200&name=Bonfy-YB-Icon%20(200%20x%20200%20px)%20(3).png)