Original article published on Substack on March 3, 2026.
Why traditional controls struggle with agent-driven workflows
As organizations accelerate the adoption of AI agents and copilots, security teams are discovering that familiar data protection models do not always translate cleanly into this new operating environment.
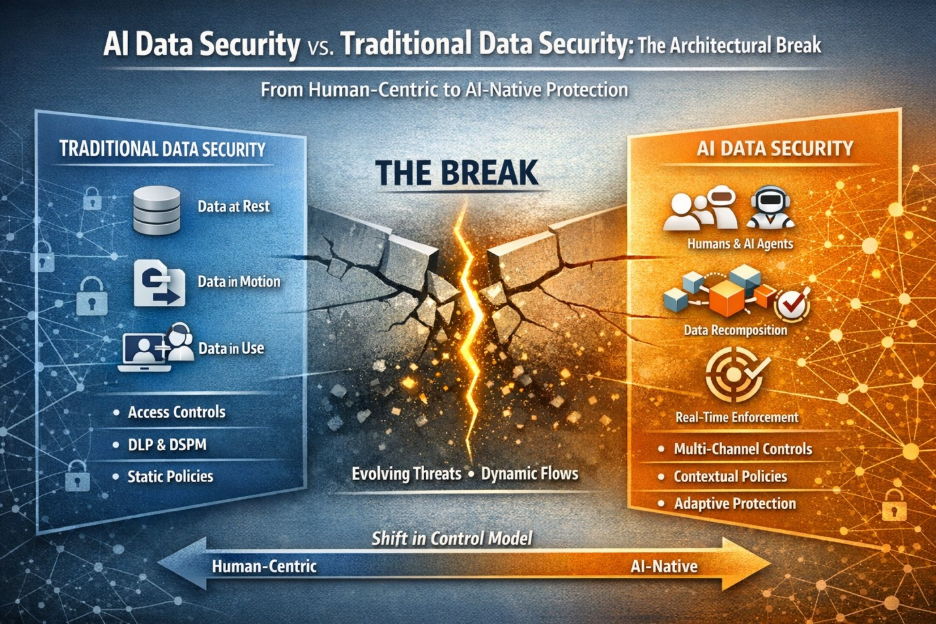
In earlier architectures, most sensitive data risk could be understood through relatively well-defined control points: data stored in repositories, data moving across networks, and user-driven actions inside known applications. While never perfect, these models provided a workable mental framework for policy enforcement and risk visibility.
Agent-driven workflows change that equation.
As discussed in my previous note, AI agents increasingly separate user intent from where actions actually execute. That architectural shift has an important downstream consequence: it activates multiple data risk surfaces simultaneously, many of which traditional controls were not designed to monitor together.
To understand what must evolve, it helps to look at agent risk through two complementary lenses.

![]()
West–East: The Expanding Data Flow Surface
The first lens is the familiar data flow axis — what can be described as the west–east movement of information across enterprise systems.
In agent-driven environments, this includes flows such as:
- data retrieved from enterprise repositories
- information moving across SaaS applications
- content shared via email and collaboration tools
- files copied or synchronized between systems
Conceptually, this is the domain where traditional data at rest and data in motion protections have historically focused.
And importantly, these controls still matter.
However, while necessary, this lens is no longer sufficient on its own. 
North–South: The Agent Control Plane
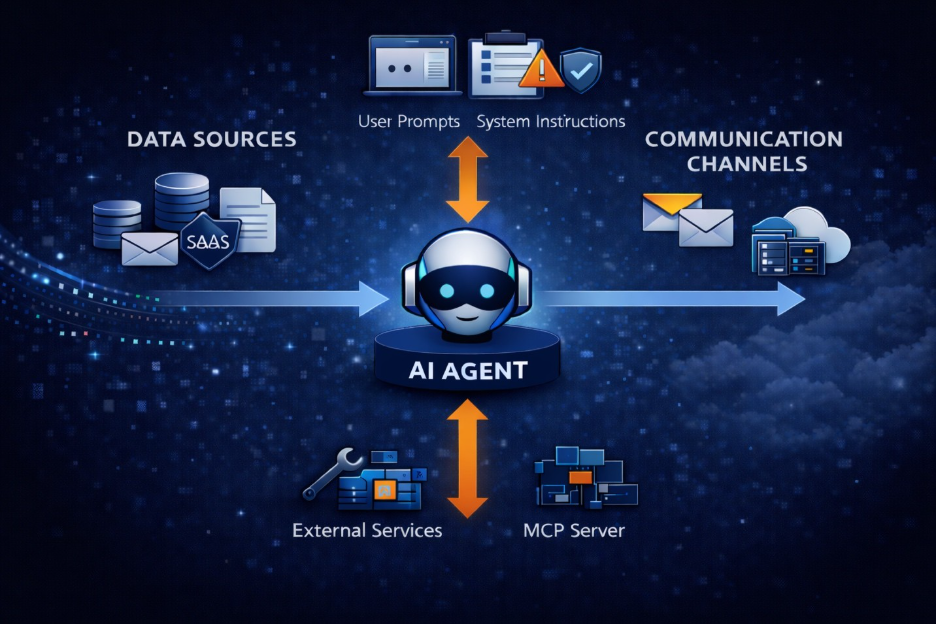
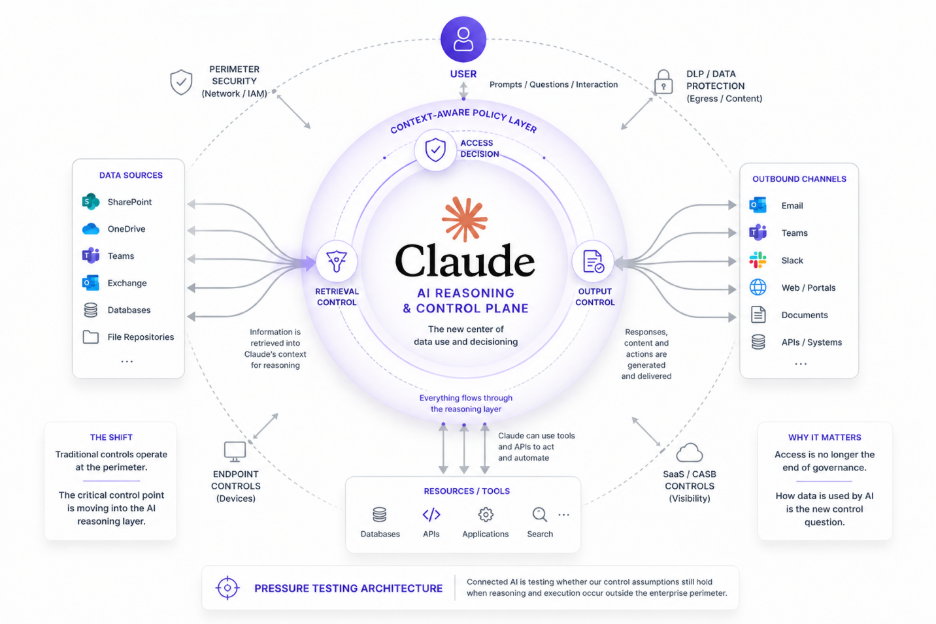
The second lens is the north–south control plane — the vertical dimension that reflects how agents interpret instructions, assemble context, and take actions.
This is where the operating model begins to diverge most sharply from traditional assumptions.
Beyond simple prompt-and-response interactions, modern agents increasingly:
- interpret user prompts
- assemble transient context through retrieval
- invoke external tools
- call MCP servers
- access internal APIs
- orchestrate multi-step workflows
- operate with delegated authority
These north–south interactions expose what is fundamentally a data-in-use problem.
The agent is no longer just moving or storing information. It is actively reasoning over it, combining sources, and making decisions inside a transient execution context.
The Often Overlooked Surface: Data in Use
Traditional data security programs have focused heavily on protecting data at rest and data in motion. Those controls remain essential.
But agent architectures elevate a third and historically harder problem: data in use.
During normal operation, agents continuously construct working contexts by combining:
- retrieved documents
- system memory
- user prompts
- tool responses
- intermediate reasoning steps
This in-use context may never be written to disk or transmitted as a complete artifact. Yet it directly influences what the agent knows, decides, and ultimately exposes.
Critically, the reasoning loop blends information at token-level granularity, often across multiple sources and trust domains. By the time an output is generated, sensitive data may already have been combined, transformed, or implicitly encoded in ways that are difficult to trace back to a single originating object.
In many agent workflows, some of the most sensitive data handling happens inside the reasoning loop itself — in a place where traditional file-, network-, or object-centric controls have limited visibility
When Data in Use Extends Beyond the Model
Data-in-use risk does not stop at the model boundary.
As agents increasingly invoke external tools, MCP servers, and supporting services, portions of the working context may be transmitted outside the primary execution environment. In some cases this includes sensitive fields, derived insights, or full prompt context embedded inside API calls.
This creates a dual exposure surface.
On one side, organizations must consider the potential for unintended data leakage into external services operating beyond traditional inspection paths. On the other, those same services can become sources of stale, manipulated, or poorly scoped information that feeds back into the agent’s reasoning loop, creating integrity risks that are often harder to detect than simple data exfiltration.
A further complication is that data-in-use exposure is not always passive.
Agent behavior can be influenced through carefully crafted prompts that attempt to override instructions, extract hidden context, or induce the agent to disclose information through downstream tool calls. Unlike traditional exfiltration paths, these prompt-driven techniques operate inside the reasoning loop itself, making them particularly difficult to detect using controls designed primarily for data at rest or in motion.
Why One-Dimensional Controls Break Down
Taken together, west–east data flows and north–south agent actions create a fundamentally different risk topology.
Most existing security stacks still evaluate exposure through a relatively narrow lens:
- endpoint activity
- email flows
- web traffic
- individual SaaS applications
Each of these remains important. But agent-driven workflows routinely cross these boundaries within a single logical task.
A user instruction may trigger:
- retrieval from a file repository (west–east)
- reasoning inside the model (north–south, data in use)
- a tool invocation via MCP (north–south)
- and downstream sharing via email or collaboration (west–east)
The enforcement challenge is also temporal. Many traditional controls evaluate data either before it moves or after it is stored. Agent reasoning loops, however, operate in real time on transient context that may exist only in memory.
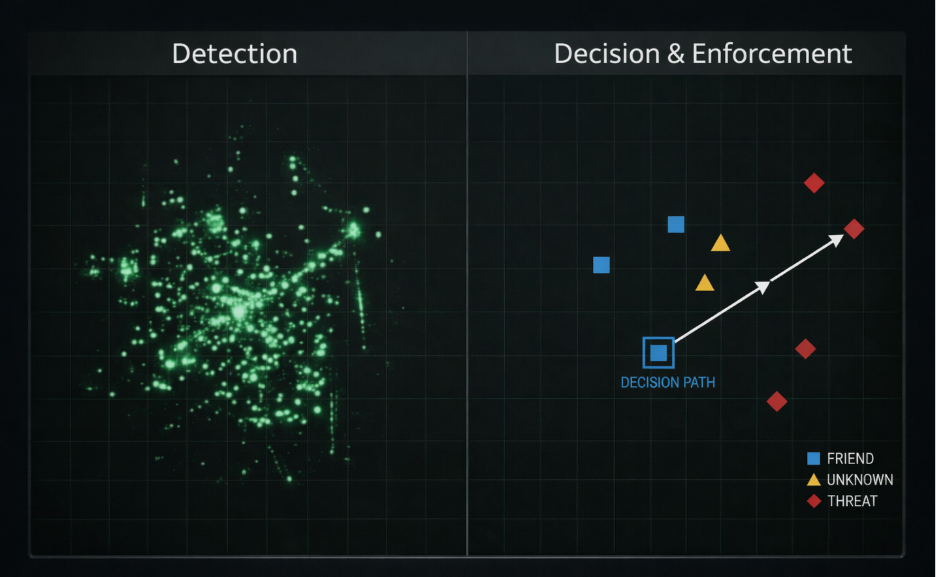
Without correlated visibility across both planes — and without the ability to reason about data in use — security teams may see isolated signals while missing the broader exposure pattern.
This is where the gap between local control coverage and end-to-end risk understanding begins to widen.
Toward Multi-Dimensional Risk Visibility
None of this implies that existing controls — endpoint protection, CASB, DLP, or classification — have lost their value. They remain important layers in the security stack.
But the center of gravity is shifting.
Effective data security for AI agents increasingly requires visibility that is:
- multi-channel — spanning email, SaaS, web, files, and agent reasoning interactions
- multi-state — covering data at rest, data in motion, and data in use
- entity-aware — understanding the users, customers, and systems involved
- workflow-aware — correlating activity across west–east and north–south planes
Security teams that continue to evaluate these dimensions in isolation will likely face growing blind spots as agent adoption scales.
Looking Ahead
AI agents are not simply another application category. They represent a new orchestration layer that stitches together data, tools, and actions across the enterprise.
As this model matures, data security architectures must evolve accordingly.
In the age of agentic AI, data protection is no longer a single-axis problem.
It is inherently multi-dimensional — and increasingly real-time.


%20(3).png?width=200&height=200&name=Bonfy-YB-Icon%20(200%20x%20200%20px)%20(3).png)