Original article published on Substack here.
Why vibe coders, citizen developers, and agentic engineers all lead to the same place: enterprise data exposure.
For most of its history, enterprise data security drew a relatively clean line between builders and users. Developers wrote code. Security teams reviewed architecture. Everyone else used the applications that resulted. That division of labor was never perfect, but it gave security programs a manageable scope. The population of people with meaningful influence over how data moved through systems was small and identifiable.
That assumption is no longer operative.
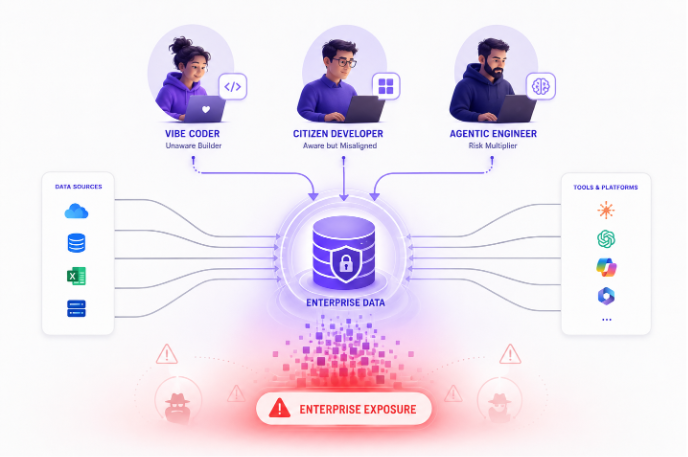
In 2026, three distinct types of builders are operating inside the enterprise simultaneously, each with a different relationship to AI, a different level of security awareness, and a different set of tools. Their flavors of risk look different on the surface. Underneath, they all lead to the same place.

The Vibe Coder: The Unaware Builder
The first type is not a developer in any traditional sense. They are a marketer automating a reporting workflow, a finance analyst building a forecasting tool, a customer success manager assembling an internal helper using Lovable, Bolt.new, or Replit Agent. Andrej Karpathy coined the term "vibe coding" in February 2025 to describe building by describing: prompting AI to generate and iterate on code without reading or reasoning through what it produces. Collins Dictionary named it Word of the Year for 2025. The practice has since spread well beyond the engineering world it originated in, reaching business users who have never written a line of code in any traditional sense.
The data security problem here is not malicious intent. It is the complete absence of a mental model for what happens to enterprise data when AI is involved. A vibe coder who instructs an AI to "pull the latest customer records and summarize them" has no framework for which data sources just came into scope, how that content was assembled into a prompt context, or where it flows after the response is generated. Security is not a dimension they have been given the conceptual tools to reason about.
The resulting exposure is structural and largely invisible. These builders create workflows that connect to real enterprise data, execute in production environments, and often run unmonitored once deployed. The workflow looks like a productivity win. From a data governance perspective, it is an ungoverned data access path.
The Citizen Developer: The Aware but Misaligned Builder
The citizen developer occupies different territory. This is the technically capable business user: the operations lead, the business analyst, the Salesforce power user, now building persistent agent workflows using platforms like Microsoft Copilot Studio, Salesforce Agentforce, or custom MCP server configurations. They understand enough to configure data connections, scope retrieval permissions, and define tool invocations. They are not building blindly.
But they are optimizing for functionality, not data boundaries. The question driving their decisions is whether the agent does what the business needs. Whether the agent has access to more enterprise data than it should, or whether its permission scope will remain appropriate six months from now, rarely enters the design conversation.
The governance gap this creates is not hypothetical. Gartner's April 2026 report "Govern Citizen Development Without Slowing Teams Down" found that organizations lacking clear governance and decision rights for citizen development will be 60 percent more likely to experience security or resiliency incidents than their peers by 2027. That gap exists not because citizen developers are careless, but because the governance infrastructure built for professional developers, including architecture review, code scanning, and deployment gates, was never designed to reach them. An agent built by a citizen developer may run for months with permissions that were never formally reviewed, connecting to data sources that expanded over time, operating with a trust model that was never stress-tested.
The Agentic Engineer: The Risk Multiplier
The third type is the professional developer. GitHub Copilot, Cursor, and Claude Code have moved from experiment to standard practice across engineering teams. What began as vibe coding has matured into what practitioners now call agentic engineering: orchestrating AI agents across multi-step workflows that connect to real systems, invoke tools, and operate with delegated authority. Nearly every engineering team is somewhere on this curve.
The professional developer understands data boundaries. That understanding, however, does not eliminate the exposure. It changes its shape.
When an agentic engineer builds an internal agent framework, they simultaneously determine the data access ceiling for every vibe coder and citizen developer who will build on top of that infrastructure. The retrieval scopes they define, the permission models they normalize, the data sources they connect: all of these propagate downstream into workflows built by people who will never revisit them. A single architectural decision made under deadline pressure can become the de facto data governance model for hundreds of automated workflows over the following year.
There is an additional exposure unique to this persona. Professional developers prompt AI coding tools with production architecture context, internal schemas, and sometimes real customer data, because that context is what makes the AI suggestions useful. That information enters external model contexts during the act of building. The data leaves the enterprise before a single line of production code runs.
Three Flavors. One Common Thread.
Each persona looks different from a security program perspective. The vibe coder does not know what they are exposing. The citizen developer knows they are building but is not thinking about exposure. The agentic engineer is thinking about it, and still creates it: both in production and upstream, during development.
The surface behaviors differ. The underlying dynamic does not.
In every case, enterprise data including customer records, internal documents, proprietary context, and regulated information is being retrieved, assembled, reasoned over, and generated into outputs by AI systems operating across workflows that security teams did not design, often did not review, and in many cases do not know exist.
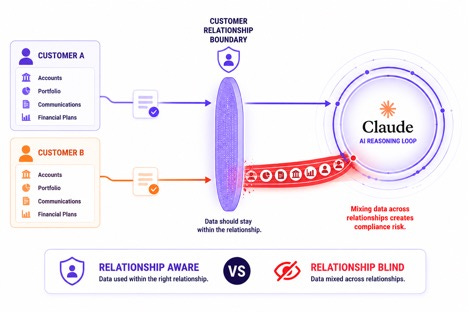
Data does not know who built the workflow that accessed it. It does not distinguish between a prompt typed by someone with twenty years of security experience and one typed by someone who learned to build last Tuesday. Sensitive information exposed through a vibe-coded automation and sensitive information exposed through a misconfigured enterprise agent represent the same regulatory risk, the same customer trust failure, and the same incident to investigate.
The three builder types matter for understanding how the exposure originated. They do not change what needs to happen at the data layer.
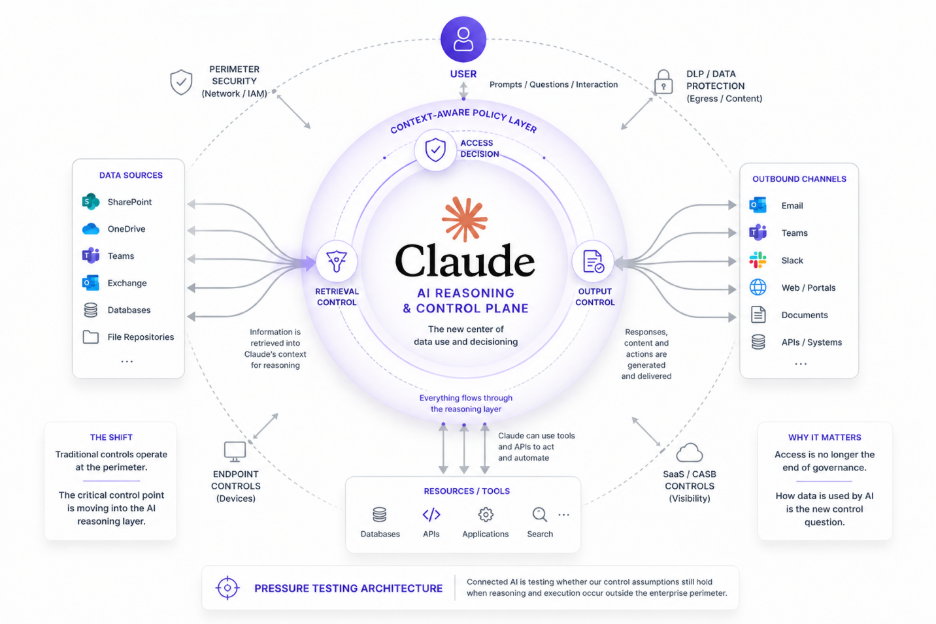
Where the Enforcement Has to Live
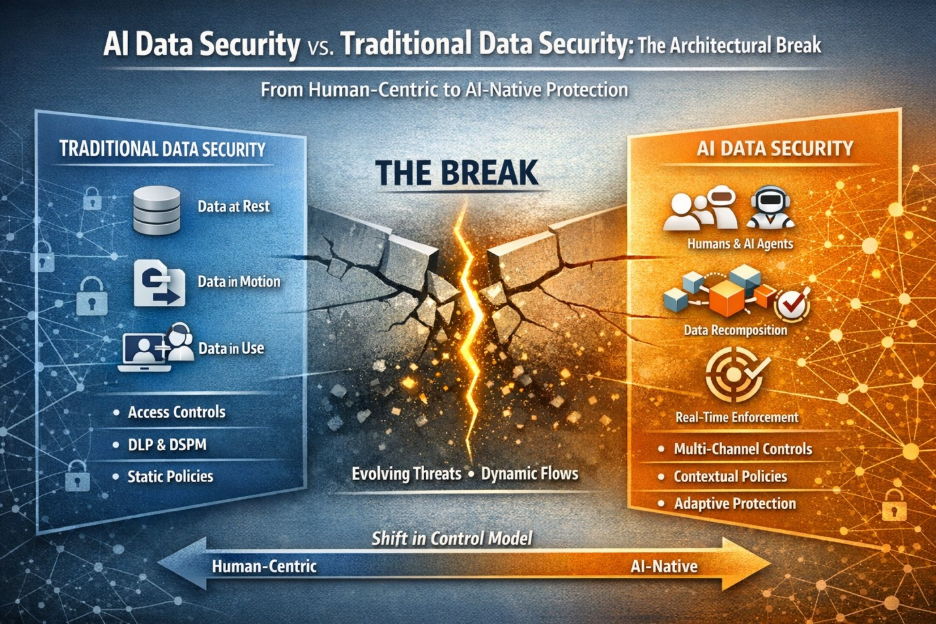
Security programs designed around a single identifiable developer population, with architecture reviews, code scanning, and defined deployment gates, were not built for this environment. They cannot scale to a builder population distributed across every business function, using tools that require no review, producing workflows that may never surface in a governance process.
The answer is not three separate governance programs, one for each persona. That path leads to incomplete coverage, inconsistent enforcement, and a false sense of control.
The only enforcement model that holds across all three is one that operates at the data boundary itself, applied uniformly, regardless of who is building, what tool they are using, or whether they understand the implications of what they have triggered. Because from the perspective of the data, there is no difference between them.
Enterprise data exposure is the common thread. The enforcement layer has to match that reality.
Original article published on Substack here.


%20(3).png?width=200&height=200&name=Bonfy-YB-Icon%20(200%20x%20200%20px)%20(3).png)