Original article published on Substack published on April 14, 2026.
Without customer context, even accurate AI becomes a liability
Customer Data Is About Trust, Not Just Sensitivity
There is a reason customer data sits at the center of so many regulations, contracts, and security programs.
It is not just because it is sensitive. It is because it exists within a relationship.
When a customer shares information with a company, they are not simply handing over data. They are placing trust. Trust that the data will be used for a specific purpose. Trust that it will not be exposed beyond what is necessary. Trust that it will not be used in ways they did not anticipate.
That expectation is reinforced everywhere. Privacy laws such as GDPR and CCPA. Industry regulations across financial services, healthcare, and insurance. Contractual commitments. Brand promises. The implicit understanding that “my data will be handled appropriately.”
When that trust is broken, the consequences are immediate. Regulatory exposure, legal risk, reputational damage, and often direct business impact.
For years, data security programs have tried to operationalize this responsibility by focusing on categories of sensitive data. Identify PII. Detect financial information. Classify health data. Apply controls.
It was never perfect, but it was workable.

AI Breaks the Old Boundaries
AI is not introducing a new category of data risk. It is exposing the limits of how we have been thinking about data.
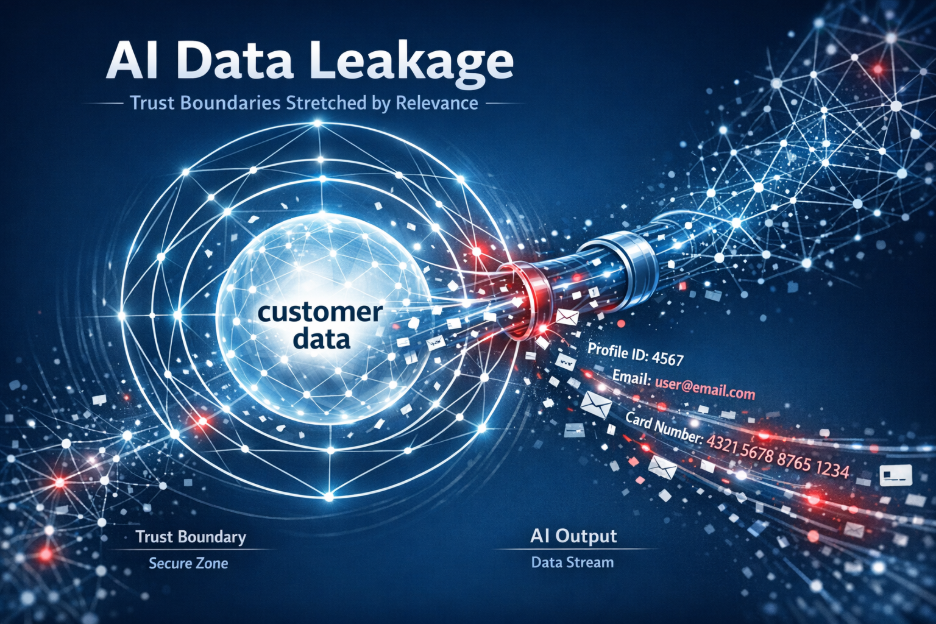
Customer data is no longer static or confined to well-defined systems. It is continuously retrieved, combined, summarized, and re-expressed across prompts, retrieval pipelines, and agent workflows. Information that used to be segmented is now brought together in a single interaction, optimized for usefulness.
That is what makes AI powerful.
It is also what makes it risky.
The boundaries that once helped enforce control, separation between systems, between internal and external views, between raw data and curated communication, are no longer reliable. The model does not understand those boundaries. It optimizes for relevance.
And relevance is not the same as permission.
The New Failure Modes: Misuse and Mis-Exposure
This shift creates two distinct failure modes.
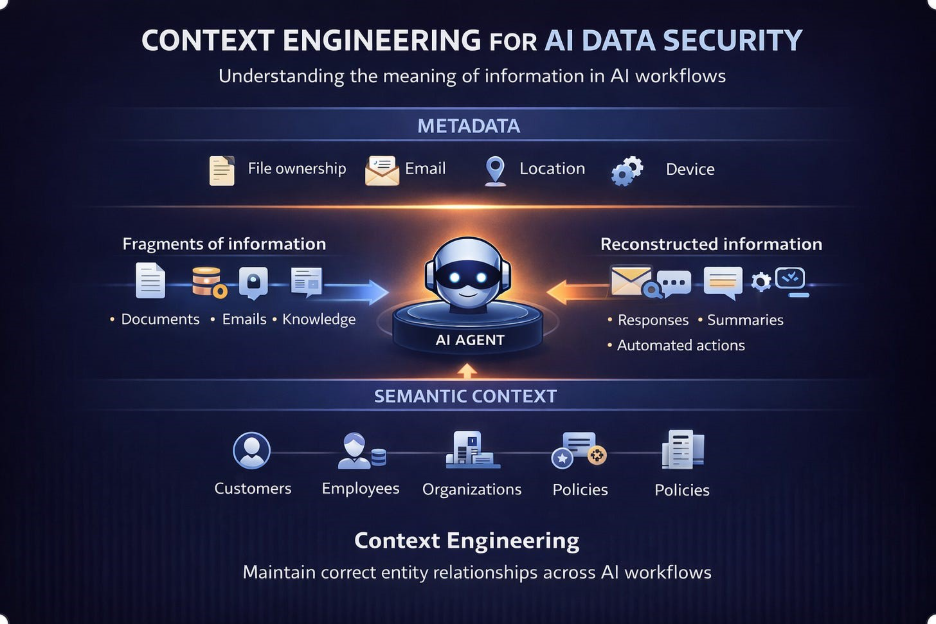
The first is internal misuse, often unintentional. Customer data ends up in places it should not be. It is included in training datasets, used in fine-tuning, or exposed through grounding sources without a clear understanding of whether it is appropriate. Teams try to make AI more useful and inadvertently expand the exposure surface.
The second is external exposure. AI-generated outputs include customer-specific details that are shared with the wrong audience or in the wrong form. A response reveals internal reasoning. A summary exposes more about a client than intended. A generated output reflects internal assessments that were never meant to leave the organization.
In both cases, nothing looks obviously wrong. There is no clear leak of a credit card number or a social security number. Nothing that a traditional rule would reliably catch.
And yet, the core obligation to protect customer data has been violated.
Why “What” Data Is No Longer Enough
Most data security technologies are built around identifying what data is. They classify content, detect patterns, and apply policies based on those classifications.
But customer protection is not fundamentally about what the data is.
It is about who it belongs to, why it exists, and whether a specific use aligns with that context.
The same piece of information can be acceptable in one situation and inappropriate in another. A claim history may be shared internally, but only partially communicated to a customer. Internal reasoning may be necessary for decision-making, but out of bounds in external communication. Customer data may be used in aggregate analytics, but not in training a model that generalizes it.
These distinctions cannot be captured by static classification.
The Missing Dimension: The “Who”
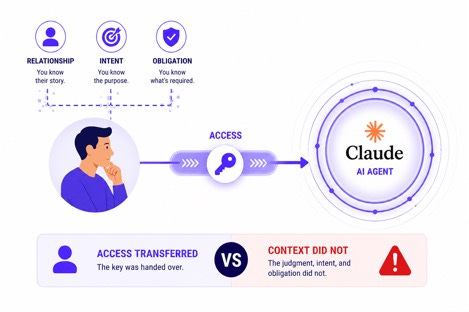
What is missing is the “who.”
Who the data is about.
Who is accessing it.
Who is receiving it.
And what the relationship between those parties allows.
Without the “who.” even accurate content analysis is not enough. You can correctly identify every entity and every fact in a piece of content and still make the wrong decision about whether it should be used or shared.
Customer-specific data is not just another category of sensitive information. Its risk is defined by relationships and expectations.
Once you introduce the “who,” the problem becomes solvable. Decisions can reflect real-world constraints, not just abstract sensitivity levels.
Relevance Is Not Permission
AI systems collapse boundaries by design. They aggregate information across systems and present it as a coherent answer. That is their value.
But they do not inherently understand appropriateness. They understand relevance.
And, again, relevance is not permission.
This is where most controls break down. They assume that if the content is correctly identified, the decision will follow. In reality, the decision depends on whether the use of that content aligns with the relationship between the parties involved.
Without that context, enforcement becomes guesswork.
From Data Classification to Contextual Decisions
This is why customer-specific data is such a dangerous blind spot.
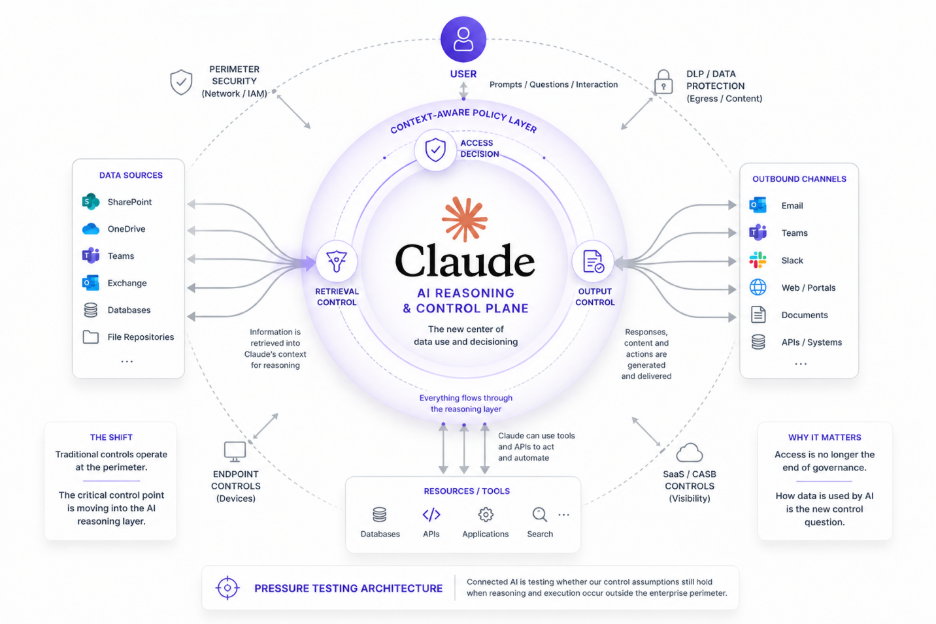
DSPM solutions can discover where data resides, but they do not govern how it should be used in real-time interactions. Traditional DLP can detect patterns, but it lacks the context to distinguish between acceptable and unacceptable uses of the same data. Even newer AI security layers often focus on model behavior without grounding decisions in the relationship between and across data.
They are all, in different ways, blind to the “who.”
And without the “who,” enforcement either becomes too rigid or too permissive. Either you block legitimate use, or you allow subtle but meaningful exposures.
Neither works.
The shift is clear:data security can no longer rely solely on identifying sensitive data and controlling its movement.
In an AI-driven world, the more important question is not “is this data sensitive?”
It is “is this use of this customer’s data, in this context, appropriate?”
Until that question can be answered reliably, customer-specific data will remain AI’s most dangerous blind spot.


%20(3).png?width=200&height=200&name=Bonfy-YB-Icon%20(200%20x%20200%20px)%20(3).png)